

Claude Code + GitHub: the 8-folder setup we use on every build
One repo. Every team member linked. Same outputs, regardless of who runs it.

Most Claude Code setups start great. You create a clean CLAUDE.md file, write some clear instructions, and the agent produces exactly what you need.
Then the project grows. Rules, domain knowledge, session state, and agent definitions all get dumped into that one file. Claude starts behaving inconsistently across sessions. The moment someone else on the team picks up the project, they have to re-explain everything to the agent from scratch.
This isn’t a prompt quality problem. It’s a file architecture problem.

Ninjabot delivers ready-to-deploy sales AI and automation tools that allows business operators to stop doing busywork and start managing leverage.
🔮 Insights from this week
Before we get into the setup, here is what I am seeing out in the market right now:
Gartner's 40% failure prediction: Gartner called out that nearly half of all AI agent projects will fail by 2027. Honestly, having cleaned up dozens of these implementations, the tech isn't the blocker. Teams are just unleashing agents before they even document their internal processes. You can't automate a workflow that doesn't exist.
LinkedIn killed the engagement pods: The feed is now LLM-based, ranking by semantic match rather than brute-force likes. If you're using automated commenting tools, the structural advantage is gone. Writing actual, useful content for real operators is mechanically favored again.
Vertical AI over SaaS: Clients are done buying software seats they have to manage themselves. We're seeing a massive shift toward selling the outcome of the labor. A human invoice coordinator is €3,000/month; an agent doing it is €600. It changes the entire pricing conversation.
💡 The one decision that fixes Claude output drift
To fix output drift, you have to separate what Claude knows, how it behaves, and where it currently is in a workflow. When you mix state, context, and rules in one file, the LLM re-interprets everything every single session.
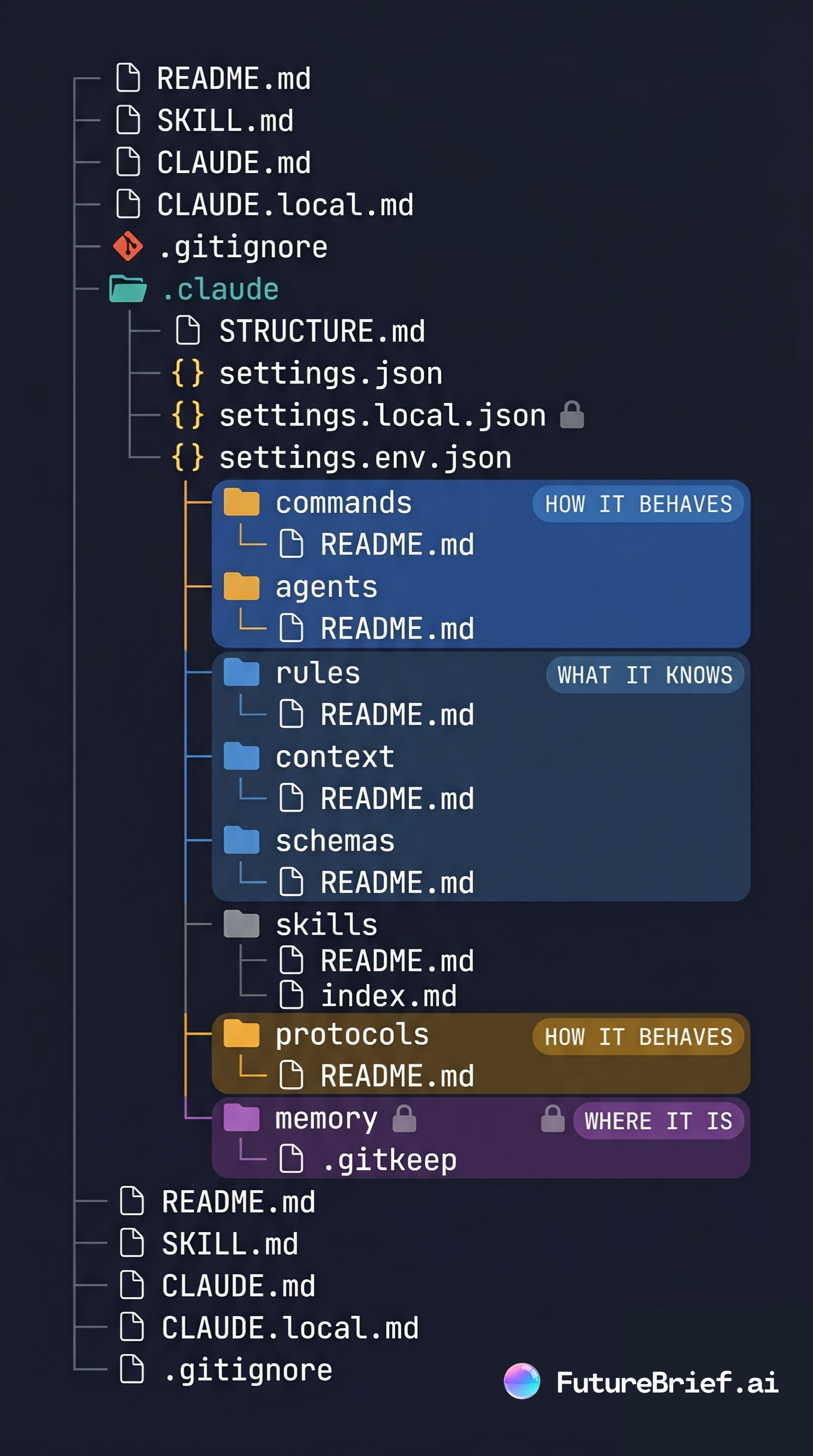
Here is the foundation of the 8-folder setup I currently use for every Claude project:
rules/
How should Claude behave? This is your code style, brand voice, and QA standards. This stuff changes slowly. Commit it to Git and apply it everywhere.
context/
What should Claude know? Think audience definitions, topic taxonomies, or approved data sources. It tells Claude facts about the world, not how to act.
memory/
Where is the workflow right now? This is purely runtime state—where the pipeline is and what just finished. It’s the only folder that changes between runs. Keep it gitignored.
The other five folders (schemas/, commands/, agents/, skills/, protocols/) layer on top of this foundation depending on the build. But separating those first three resolves 90% of your consistency issues.
What the setup actually looks like in practice
Your .claude/ folder sits at the project root right next to CLAUDE.md. The markdown file itself should just be a routing board. If it doesn’t fit on one laptop screen without scrolling, it’s too long.
The workflow is straightforward: create a Claude Project, then attach your GitHub repo in the file settings. Claude Code will update the local repo during active sessions, and manual edits go straight to Git in between. Since everyone on the team links their own Claude Project to that same repo, one committed folder structure becomes the shared brain. Day one behavior matches day ninety.
At the .claude/ root, you also need a settings.json to define which tools Claude can use and what paths it’s allowed to write to. I highly recommend adding a settings.env.json as well so you don’t accidentally leak dev behavior into production.
Four places I see teams break this
1. Stuffing rules with context People love putting audience personas into the rules/ folder because it feels like an instruction. It’s not. Before putting a file in there, ask yourself: does this tell the agent how to act, or what to know? If it’s knowledge, move it to context.
2. Treating memory as a permanent database Last month I saw a state.json file swell up because an agent kept appending entire chat histories into it. Eventually, it got gitignored and wiped during a commit, taking weeks of refined project history with it. Memory is for workflow position only. If it needs to survive a session reset, put it in context.
3. Refusing to delegate the CLAUDE.md file Adding subfolders doesn’t help if you still keep 400 lines of instructions in your root CLAUDE.md file. You’re just recreating the exact same problem in a slightly different location. Use it as an entry point, not a dumping ground.
4. Updating the repo but forgetting to sync Your team pushes an update to the repo (a new context file, a revised rule) but nobody hits “Sync” in the Claude Project settings. The agent operates blindly on the old version, and you spend three hours debugging a prompt that isn’t actually broken. Make the project sync part of your core commit habit.
🔧 Tools & Resources
Claude Code: Reads the structure perfectly at session start and handles slash commands.
Cursor: If you're mixing Cursor and Claude Code, make sure your .cursorrules file at the project root doesn't contradict your .claude/ folders. Mid-session conflicts between the IDE and the agent are a nightmare.
Obsidian (+ Git plugin): I use this to keep the context/ folder human-readable. It lets non-technical stakeholders update audience docs without ever having to open a terminal.
📥 Steal my template
I packaged this exact architecture into a ready-to-use template repo. It has the CLAUDE.md router, all eight subfolders, starter settings files, and a SKILL.md that scaffolds the whole thing.
Clone it here.
Btw you can import the SKILL.md file into your Claude as a skill and just use it in your next Claude code build.
Three questions. Eight folders. One structural separation.
Stop mixing your information types and the consistency will follow.
Build with calm,
P.S. On my LinkedIn I share short tech updates and early previews of topics before they become newsletter issues.